Custom KMeans Algorithm
In this small project, I implemented a custom kmeans algortihm.
import matplotlib.pyplot as plt
from matplotlib import style
style.use('ggplot')
import numpy as np
X = np.array([[1, 2],
[1.5, 1.8],
[5, 8 ],
[8, 8],
[1, 0.6],
[9,11],
[8,2],
[10,2],
[9,3]])
# plt.scatter(X[:,0], X[:,1], s=150)
# plt.show()
colors = 10*["g","r","c","b","k"]
#assign every feature a cluster center
#optimize until convergence
class Mean_Shift:
def __init__(self,radius=4):
self.radius = radius
def fit(self, data):
centroids = {}
for i in range(len(data)):
centroids[i] = data[i]
while True:
new_centroids = []
for i in centroids:
in_bandwidth = []
centroid = centroids[i]
for featureset in data:
if np.linalg.norm(featureset-centroid)<self.radius:
in_bandwidth.append(featureset)
new_centroid = np.average(in_bandwidth, axis = 0)
new_centroids.append(tuple(new_centroid))
uniques = sorted(list(set(new_centroids)))
prev_centroids = dict(centroids)
centroids = {}
for i in range(len(uniques)):
centroids[i] = np.array(uniques[i])
optimized = True
for i in centroids:
if not np.array_equal(centroids[i], prev_centroids[i]):
optimized = False
if not optimized:
break
if optimized:
break
self.centroids = centroids
def predict(self,data):
pass
clf = Mean_Shift()
clf.fit(X)
centroids = clf.centroids
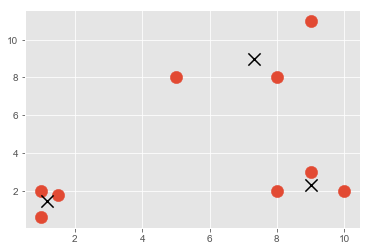
plt.scatter(X[:,0], X[:,1], s=150)
for c in centroids:
plt.scatter(centroids[c][0], centroids[c][1],color='k', marker='*',s=150)
plt.show()
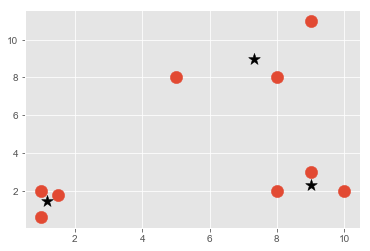
Compare with sklearn kmeans:
#Sklearn KMeans
from sklearn.cluster import KMeans
clf2 = KMeans(n_clusters=3)
clf2.fit(X)
centroids2 = clf2.cluster_centers_
centroids2 = np.array(centroids2)
plt.scatter(X[:,0], X[:,1], s=150)
for c in range(len(centroids2)):
plt.scatter(centroids2[c][0], centroids2[c][1],color='k', marker='*',s=150)